Je winkelwagen is leeg
Producten die je toevoegt, verschijnen hier.
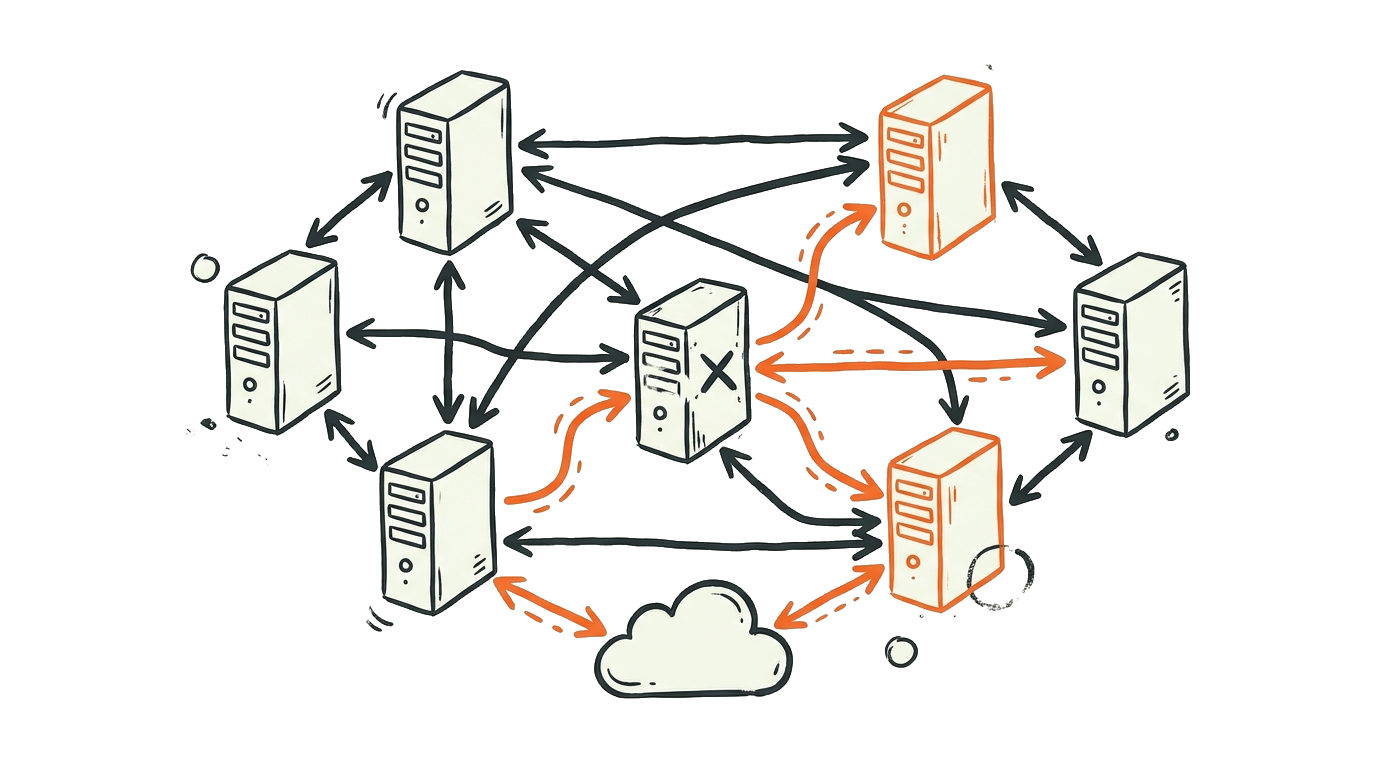
High-availability (HA) garandeert continue beschikbaarheid van systemen met minimale downtime.
Het concept van high-availability computing ontstond in de jaren 1960-1970 uit de behoefte aan betrouwbare systemen voor missiekritische toepassingen in sectoren zoals bankwezen, telecommunicatie en luchtvaart. Een belangrijke pionier was Tandem Computers, opgericht in 1974 door Jimmy Treybig. Hun "NonStop" fault-tolerant systemen gebruikten redundante hardware-componenten en hadden een uptime van jaren in plaats van dagen.
In de jaren 1980-1990 kwam clustering-technologie op, waarbij meerdere computers als één systeem konden samenwerken. Digital Equipment Corporation introduceerde VAXcluster in 1983, een baanbrekend clustersysteem dat alle single points of failure verwijderde. Deze systemen waren beperkt tot 90 meter afstand tussen nodes, maar latere versies over Ethernet en FDDI maakten geografische spreiding mogelijk voor disaster recovery.
De jaren 2000 brachten virtualisatie, waardoor live migration van workloads mogelijk werd. Platforms zoals VMware introduceerden ingebouwde HA-features. Het tijdperk van cloud computing (AWS, Azure, Google Cloud) vanaf 2010 maakte high-availability toegankelijk voor organisaties van elke omvang. Containerisatie met Docker en Kubernetes introduceerde nieuwe benaderingen, en concepten zoals "chaos engineering" ontstonden om systemen proactief te testen op veerkracht.
Vandaag de dag is high-availability geen luxe meer maar een verwachting. Met de groei van e-commerce, SaaS-applicaties en digitale diensten is continue beschikbaarheid een directe business performance indicator geworden, waarbij zelfs enkele minuten downtime kunnen leiden tot aanzienlijke omzetverliezen.